VL JEPA: A Deep Dive into Vision-Language Predictive Models
VL JEPA (Vision-Language Joint Embedding Predictive Architecture) is Meta AI’s innovative approach to self-supervised learning, designed to bridge the gap between vision and language understanding without relying heavily on labeled data.
Introduction to VL JEPA
VL JEPA was introduced by Meta AI as part of their broader effort to advance self-supervised learning. Unlike traditional supervised models that rely on massive labeled datasets, VL JEPA learns by predicting contextual embeddings across modalities. This makes it more scalable and adaptable to real-world data where labels are scarce.
Core Architecture
The architecture of VL JEPA is built on joint embedding spaces where both vision and language inputs are projected. A predictor network then learns to forecast missing or masked embeddings, enabling the model to capture semantic relationships between text and images. This design reduces reliance on reconstruction losses and instead focuses on representation alignment.
Training Paradigm
"Predictive learning is not about reconstructing pixels, but about capturing meaning."
VL JEPA leverages a self-supervised predictive learning paradigm. Instead of reconstructing raw inputs (like pixels or words), the model predicts embeddings in a joint space. This approach is more efficient and avoids the pitfalls of generative reconstruction, focusing instead on semantic alignment. By masking parts of the input and predicting their embeddings, VL JEPA learns robust cross-modal representations that generalize well.
Applications
VL JEPA has wide-ranging applications across AI research and industry:
Image-Text Retrieval: Matching images with descriptive text and vice versa.
Visual Question Answering: Answering questions about images using joint embeddings.
Content Moderation: Detecting harmful or misleading multimodal content.
Assistive Technology: Helping visually impaired users by aligning textual descriptions with visual inputs.
Foundation for Multimodal AI: Serving as a backbone for models that integrate vision, language, and potentially audio.
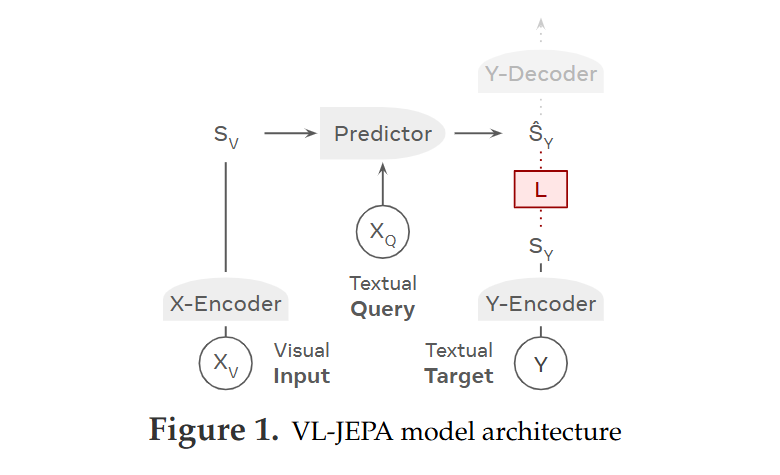
VL JEPA Architecture Diagram
To better understand how VL JEPA works, here’s a simplified flow of its architecture:
Vision Encoder: Processes raw images into embeddings.
Language Encoder: Converts text into embeddings.
Joint Embedding Space: Aligns vision and language representations.
Predictor Network: Learns to forecast masked embeddings.
Masked Embeddings: Provide the self-supervised training signal.
Figure: VL JEPA architecture showing vision encoder, language encoder, joint embedding space, and predictor network.
Future Directions
VL JEPA represents a step toward more general-purpose multimodal AI. Future research may expand its predictive embedding approach to include audio, video, and 3D data. Additionally, integrating reinforcement learning and human feedback could make VL JEPA more aligned with user needs. The long-term vision is to create models that understand and reason across multiple modalities seamlessly.
VL JEPA is not just a model—it’s a paradigm shift toward predictive, multimodal intelligence.